 RSS2 Feed RSS2 Feed |
 |
| CSE HTML Validator Std. and UTF-8 & Link Check |
|
Having installed CSE HTML Validator Std. 11 PhpED 6.2 build 6236 (trial mode) automagically picked up this instead of the built-in Lite version the next time it was run. The path to CSE in Settings is correct, and changing the number of errors & warnings in CSE Validator is reflected by validation messages in PhpED. Also there are messages the Lite version would not show. So obviously the right setup is used.
However, there are two issues: A) In a UTF-8 text cyrillic characters, umlauts, diacritics are marked as errors (characters between 128 and 159). The file was saved as UTF-8, the project defaults to UTF-8, and the status line shows UTF-8. Neither in TopStyle nor in its own editor CSE Validator raises these errors. Also in the browser the file displays fine. Need there be any further setting within PhpED to tell the validator specifically about the file's encoding? B) Link check through CSE Validator runs, but links actually are not checked. In the log pane all links (both relative and absolute) are listed as Type=Script (whatever the link links to, PHP, HTML, JPEG), with a suffix to the path of [not checked]. Again there is no such problem in TopStyle or CSE's own editor. Validator Engine is set to check links in the background besides. Any insight to solve either issue? System is XP SP4 BTW. TIA |
||||||||||||
|
_________________ JH |
|||||||||||||
|
Site Admin
|
You didn't say what the error messages were shown. They might be okay and might be not. The fact that CSE didn't show them, does not mean CSE didn't send them to the IDE because IDE runs the requests with all warnings/errors enabled (no filters) while CSE's own editor may filter something out.
Anyway, it should be sent to CSE authors first -- they'd explain the nature of the errors/warnings. Regarding links, I'm sure you want to show us an example. Please do by contacting SUPPORT http://www.nusphere.com/contact_us |
||||||||||||
|
_________________ The PHP IDE team |
|||||||||||||
|
Result in Log looks like this: Script ../miscell/14683_d.php [not checked] 19:11:07 15684_d.php Script images/15684_10_detail.jpg [not checked] 19:11:07 15684_d.php Script images/15684_20.jpg [not checked] 19:11:07 15684_d.php Script 11966_d.php [not checked] 19:11:07 15684_d.php Script images/15684_07.jpg [not checked] 19:11:07 15684_d.php Script http://www.example.com/books/28949_d.php [not checked] 19:11:07 15684_d.php Script #internalLink [not checked] 19:09:24 15684.php Timeout is set to 30 secs in CSE Validator, the server is available (local Apache) and works in browser. Result appears almost instantly in Log pane. In TopStyle, using the same CSE setup, link check works fine, incl. for the very same file. |
||||||||||||||
|
_________________ JH |
|||||||||||||||
|
Just try this code snippet noname4.php:
The error message is something like this:
In TopStyle the same code snippet, saved as UTF-8 and recognized as such, would produce no error or warning when checked against "All". Same for CSE Editor. In PhpED the error goes away if in CSE Validator Engine Options -> Miscellaneous -> Check for characters 128-159 (does not apply to Unicode encoded documents) is unchecked. As some projects use ISO-8859-1 this is no option though. From CSE Help:
The project is set to UTF-8, PhpED defaults to UTF-8, the font is Unicode (Courier New) and the same font is used in TopStyle et al. I do not know the CSE API, but it seems to me as if PhpED does not pass the correct file encoding (UTF-8) to CSE or even attempts some conversion, probably to system default (XP SP4), while there is no such interference from TopStyle. |
||||||||||||||||||||
|
Last edited by jayaitch on Thu Apr 05, 2012 3:05 pm; edited 1 time in total _________________ JH |
|||||||||||||||||||||
|
Site Admin
|
If your "UTF-8" file contains characters in that range - it is not a UTF-8 file because this encoding does not allow characters in this range.
If CSE while running under PhpED does complaint about them - it is correct If CSE while running out of PhpED does not complaint about them - it is either incorrect or corresponding setting or check is OFF. btw fonts have no relation to file encoding. |
||||||||||||
|
_________________ The PHP IDE team |
|||||||||||||
|
So a file saved in PhpED as UTF-8 is not a UTF-8 file, yet those other "broken" applications - like SciTE, TopStyle, CSE Editor, browsers - can handle it as UTF-8 fine. Very funny.
Deliberately opening the very same file as ANSI in SciTE the expanded double byte characters easily demonstrate why in PhpED CSE issues seemingly silly suggestions as to replace certain characters by the & euro; entity: it is obvious PhpED passes the file to CSE as ANSI, not UTF-8. I can send you the file offlist if you like. Anyway, as PhpED 6.2 ships with CSE Validator Lite version 6.52.2 dating back to 2004 it looks like PhpED uses not only an ancient version of CSE, but also a dated interface. Posting the issue to the CSE forum CSE's Albert Wiersch had this to say:
Actually, using the 8 (sic!) years old 6.5 version those errors go away - and return when switching back to the current version of CSE. Presumably for the same reason link check is not working (see above posting of March 19).
reads NuSphere's latest email newsletter advertising version 7.0. That PhpED can't integrate with more current versions of CSE - and probably still ships with a validator back from 2004 - is the more discouraging as CSE Validator Lite is at version 11 by now. And already was at 10 when PhpED 6.2 shipped. jayaitch |
||||||||||||||||
|
_________________ JH |
|||||||||||||||||
|
Site Admin
|
It's a very strange and inaccurate interpretation of situation.
Why do you think so? Whenever you save a file in PHPED and use UTF-8 encoding, it's always saved as UTF-8 - it means that no other characters can appear in the file but UTF-8 ones.
If a file contains non-UTF-8 characters, you can't call it a file encoded in UTF-8. If you try to open such file, PhpED will suggest to either change encoding or force transliteration for wrong characters. It won't silently replace them as some other "good" editors do. For example, if your file contains just one 0x81 character, how according to your logic this byte should be interpreted by a "good' editor?
Absurd. All strings PhpED passes to CSE are UTF8 encoded. Look at this screenshot: 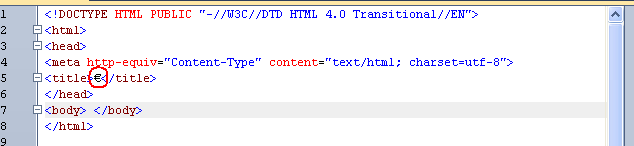
and this file is sent to CSE as the following bytes: 0x3C, 0x21, 0x44, 0x4F, 0x43, 0x54, 0x59, 0x50, 0x45, 0x20, 0x48, 0x54, 0x4D, 0x4C, 0x20, 0x50, 0x55, 0x42, 0x4C, 0x49, 0x43, 0x20, 0x22, 0x2D, 0x2F, 0x2F, 0x57, 0x33, 0x43, 0x2F, 0x2F, 0x44, 0x54, 0x44, 0x20, 0x48, 0x54, 0x4D, 0x4C, 0x20, 0x34, 0x2E, 0x30, 0x20, 0x54, 0x72, 0x61, 0x6E, 0x73, 0x69, 0x74, 0x69, 0x6F, 0x6E, 0x61, 0x6C, 0x2F, 0x2F, 0x45, 0x4E, 0x22, 0x3E 0x3C, 0x68, 0x74, 0x6D, 0x6C, 0x3E 0x3C, 0x68, 0x65, 0x61, 0x64, 0x3E 0x3C, 0x6D, 0x65, 0x74, 0x61, 0x20, 0x68, 0x74, 0x74, 0x70, 0x2D, 0x65, 0x71, 0x75, 0x69, 0x76, 0x3D, 0x22, 0x43, 0x6F, 0x6E, 0x74, 0x65, 0x6E, 0x74, 0x2D, 0x54, 0x79, 0x70, 0x65, 0x22, 0x20, 0x63, 0x6F, 0x6E, 0x74, 0x65, 0x6E, 0x74, 0x3D, 0x22, 0x74, 0x65, 0x78, 0x74, 0x2F, 0x68, 0x74, 0x6D, 0x6C, 0x3B, 0x20, 0x63, 0x68, 0x61, 0x72, 0x73, 0x65, 0x74, 0x3D, 0x75, 0x74, 0x66, 0x2D, 0x38, 0x22, 0x3E 0x3C, 0x2F, 0x68, 0x65, 0x61, 0x64, 0x3E 0x3C, 0x62, 0x6F, 0x64, 0x79, 0x3E, 0xE2, 0x82, 0xAC, 0x3C, 0x2F, 0x62, 0x6F, 0x64, 0x79, 0x3E 0x3C, 0x2F, 0x68, 0x74, 0x6D, 0x6C, 0x3E as you can see Euro was sent in UTF-8 and btw CSE did not complain about it. So I think -- it's something wrong with your HTML file. Probably it does not contain Content-Type charset.
It's not a matter of interfaces or versions. It's a matter of stability. In fact no newer versions of CSE Lite would work stable under PhpED -- they crash almost immediately after some calls because CSE is trying to show nag window and does so in the thread the library is called in. Because we use a dedicated worker thread for all kinds of background processes, CSE calls GUI functions from this thread. CSE is written in a library that it's not intended to call GUI from threads other than main thread and such calls results in crashes in CSE itself. Some years ago I already contacted Albert, but seems he didn't find a proper solution for us. BTW you can try your best and pass your questions to him |
||||||||||||||||||||
|
_________________ The PHP IDE team |
|||||||||||||||||||||
|
you wrote March 20. And now:
Needless to say the file was saved in PhpED as UTF-8 as by the original description of the issue (though not in one sentence and not all capitals). Needless to say as well that opening the file in PhpED won't suggest any transliteration. It's left to the reader's exercise to consider why this might be.
The hex view is irrelevant. Without explicit declaration UTF-8 as any other Unicode flavour is one byte character soup exactly like ANSI. Open your UTF-8 file as ANSI in an editor (open, not convert) and then see euro signs and other funny characters in this UTF-8 file which were not there when shown as UTF-8. As suggested before. Anyway, you demonstrate this by your own hex view: 0x82, marked in red.
This is the first clue as the file indeed does not contain the <meta http-equiv="content-type" content="text/html; charset=UTF-8"> header - as this is within the header template included per <?php include header.inc.php ?> as indicated in the code sample provided previously. To state the obvious: the included header template is part of the same project as the file in question. And it is UTF-8, too, saved as such in PhpED (sic!). Converting the file into plain HTML with all headers incl. charset=UTF-8 (saved in PhpED, saved as UTF-8, CSE v.11 set in PhpED options) the errors go away. Changing charset to "iso-8859-1" (still saved in PhpED, still saved as UTF-8, still CSE v.11 set in options) the errors return. If in this matter anything is absurd, then it's that a modern IDE for PHP, a language built to use templates and includes, is not passing the file encoding (which it recognizes very well otherwise), but leaves it to CSE to find a full-blown charset header. Leaving aside for a moment that according to your statements applications like TopStyle or CSE Editor (GUI) are broken, CSE Validator is not fooled there by simply changing the charset header to "iso-8859-1" while the actual encoding still is UTF-8 as saved in PhpED.
Specifying csevalidatorV110.dll in External Tools->CSE Validator did not crash PhpED in a couple weeks. After all DLL is about integration, not GUI. Besides the web evolved a quite bit since 2004, so it would seem to be better to include rather no validator than an ancient version no one can update anymore to activate e.g. link checking (which is included in PhpED options). I have passed your reply to the CSE forum with reference to the whole thread (the problem as such was presented there already). As I can consider this issue only as being handled in an anti-solution, even anti-problem manner from the start, any further continuation of this thread can only aggravate the matter. JayAitch |
||||||||||||||||||||||
|
_________________ JH |
|||||||||||||||||||||||
|
Site Admin
|
Looks like you don't understand it clear. Euro in UTF-8 is not just 0x82. It is all three bytes - 0xE2, 0x82, 0xAC, it is UTF-8, multibyte encoding.
Furthermore I demonstrated you that it works even with this "old" CSE version and does not produce any errors nor warnings. So I assume it's something wrong with what you're doing, not with phped or CSE. If you split your HTML file into multiple files and have <meta> somewhere else, the result you get is not html that you can validate as a single file. So don't blame at phped or CSE. They work as they should. IF you don't have <meta> in html, don't expect CSE to understand the encoding. |
||||||||||||
|
_________________ The PHP IDE team |
|||||||||||||
|
I do understand the multibyte character of the euro sign in Unicode. The problem is not an actual euro symbol in UTF-8, but the 0x82 part (or similar) when passed to CSE. Actually, the file in question has no euro symbol at all, it is just those bytes which are legal part of multibyte strings while being illegal as singlebyte characters which cause CSE to suggest using entities, incl. the one for the euro symbol. I suppose that in Windows-1252 codepage Microsoft has abused the 128-159 range i.a. for the euro symbol, so the confusion here arose. Matter of fact, if deliberately opening a Unicode file as ANSI in place of the multibyte characters pairs of all sorts of funny characters show, incl. the euro symbol.
AFAICT this following option in CSE->Validator Engine Options->Miscellaneous
is responsible for the errors raised. It is enabled by default. IIRC in the Lite version, or at least back in CSE 6.5 Lite this option is not available and supposedly the 128-159 range never checked (thus no errors with 6.5 Lite). However, in v.11 Std. it is, and if I disable this option the errors go away. While disabling would be a workaround for the whole affair, I rather have it enabled as we also have ISO-8859 projects. Actually we are on the way to drop Homesite for its lack of Unicode support, so in this period of testing replacement applications all but a few files are still ISO-8859 encoded. With a base of 15-20k files this also makes this issue so important for us. Else I might just say Who cares? Now PhpED, TopStyle, CSE's own editor, SciTE, to name but a few, try to recognize if a file is Unicode (multibyte) encoded even if there is no BOM, no shebang, no <meta> or other encoding declaration, and in case open it as Unicode. PhpED has an extra safety net by the Transliteration dialog. However, there must be some difference when it comes to passing the file to CSE for if passed by e.g. TopStyle CSE obviously knows it is Unicode and treats it as such (thus does not check the 128-159 range as stated per above option). Yet if passed from PhpED this particular information is either never sent, lost or the data stream is even wrongly declared as ANSI. I am no programmer and don't know how the integration with CSE works. Only thing I know is that with various other applications it works, which suggests that the validator does no guessing about the encoding, but needs some additional information about the file being passed, either within the file (e.g. <meta>) or by some other means, or else treats it just as singlebyte character soup. An expert exchange with Albert should clear this easily. As for splitting HTML I should think that in our days of dynamic sites with templates and code snippets put together just before being delivered to the user's browser the lack of encoding declarations should cause no grievance whatsoever. Actually with PHP the existence of a BOM even is a no-go. Again, neither PhpED nor other serious editors have problems with recognizing the encoding of such code parts. And particularly PhpED with its appreciated transliteration safety net should have no trouble passing the recognized and if necessary even confirmed information about the encoding to some other application. I hope this helps for clarification and brings together our deviating trains of perception. Simply put the whole issue seems to boil down to two things: 1) CSE Lite 6.5 does not check the 128-159 character range at all; 2) for to make this check work current (paid) versions of CSE (or csevalidator.dll) require information about the file encoding being passed one way or another. JayAitch PS: For information I forward a copy directly to Albert. |
||||||||||||||
|
|
|||||||||||||||
|
Site Admin
|
1) not only paid but all versions of CSE should support checking for valid characters (regarless of the ranges) 2) currently it's not supported by CSE or at least I'm not aware of this. I mean I don't know how to tell CSE what file encoding is. Without this info CSE can't make validation in a right way. Indeed - Content Type with charset can be sent by the web server as a regular header and therefore META charset may not appear at all, or like in your case it appears in another file.
Well, we send files in UTF8 and seems 6.5 isn't design to work with UTF8 at all and treat all the passed as an ANSI content...whatever ANSI is configured in OS... Uffff. That's bad. But... What Albert suggests -- sending content of the files to CSE in Unicode (UTF16LE), does not look any better. I'm not sure how this would help validate the files in a right way. For example: if underlying file is ISO-8859-1 encoded and a Euro sign added in the editor, PhpED will detect this error only upon saving the file because this symbol is NOT in ISO-8859-1 table. It still will be validated as correct because this symbol is perfectly valid in UTF16LE, and CSE does not know that the file should be checked against ISO-8859-1 bounds. |
||||||||||||||||
|
_________________ The PHP IDE team |
|||||||||||||||||
|
Well, back in 2004 Unicode probably wasn't that hot yet. And it was good practice to use HTML entities for all characters above 127. With ISO-8859-X it still is I think, at least if using more than just umlauts. FWIW there was an option Allow numeric references 128-159 (= numeric entities) unchecked by default in CSE Lite 6.5 and still is per Validator Engine Options -> Char References. Obviously the check for unencoded characters in this range (Check for characters 128-159 (does not apply to Unicode encoded documents)) was added only later.
I can see the problem with the UTF-16 approach, as long as there is no further information about the actual encoding sent. IIRC internally Subversion saves everything in Unicode, but the respective real encoding still must be preserved somewhere, too, or things would go wrong. It doesn't seem relevant here anyway. However, I don't think the file has to be saved before PhpED detects the error. Just entered the euro sign in an ISO-8859-1 file and without saving the error was thrown. But then PhpED is very smart about dealing with unsaved changes in Search/Replace in Files, too. Nor does a file have to be saved in TopStyle or CSE Editor before validation. Inserting the euro sign in either of these results in the 128-159 range error if the file is ISO-8859-1 and is accepted if the file is UTF-8 in both. I suppose those digits in the commandlines for CSE HTML Validator in Settings->Integration (e.g. "@FName@" 0) are flags internal to PhpED's integration of CSE? For at least they don't relate to CSE's own ALT-[0-9] keyboard shortcuts nor to the option flags of cmdlineprocessor.exe, at least not with v11. Anyway, removing those digits makes no difference, nor does changing the executable to the DLL found in %SYSTEM% (which is identical with the one in CSE installation directory anyhow). Just being curious - I am no programmer beyond some scripting in PHP, JS, Perl, Python - I just had a look into CSE developer DLL files and see there are functions for both ANSI and Unicode (csefunctionpointerassign.cpp). However, particularly the third one of these bits in csevalidator.h seems relevant, also considering their respective version information:
There also is a section "link checking flags" marked as new as of v8.9910 which might explain why links were not checked with v11 here. JayAitch |
||||||||||||||
|
|
|||||||||||||||
| CSE HTML Validator Std. and UTF-8 & Link Check |
|
||
|
|
Content © NuSphere Corp., PHP IDE team
Powered by phpBB © phpBB Group, Design by phpBBStyles.com | Styles Database.
Powered by
Powered by phpBB © phpBB Group, Design by phpBBStyles.com | Styles Database.
Powered by